Entry
Reader's guide
Entries A-Z
Probit Analysis
Probit analysis originated as a method of analyzing quantal (dichotomous) responses. Quantal responses involve situations in which there is only one possible response to a stimulus, sometimes referred to as “all-or-nothing.” Early applications of probit analysis involved biological assays. A classic example involves the determination of death when an insect is exposed to an insecticide. Although theoretically the health of the insect deteriorates as exposure to the insecticide is increased, measurement limitations or focus on a specific result necessitate the use of a dichotomous variable to represent the quantal response. Current applications in the social sciences often involve individual-level behavior such as whether a member of Congress votes for or against a bill or when a judge affirms or reverses a lower court decision.
Analytical work in the social sciences often uses a form of linear regression analysis (e.g., ordinary least squares [OLS]). A fundamental assumption of regression analysis is that the dependent variable is continuous, which allows for a linear model. Many research questions, however, involve situations with a dichotomous dependent variable (such as the decision making of human actors, with a prime example being individual voting behavior). Because certain regression assumptions are violated when the dependent variable is dichotomous, which in turn may lead to serious errors of inference, analysis of dichotomous variables generally requires a nonlinear estimation procedure, and probit is a common choice.
The conceptual approach of regression is to estimate the coefficients for a linear model that minimizes the sum of the squared errors between the observed and predicted values of the dependent variable given the values of the independent variables. In contrast, the approach of probit is to estimate the coefficients of a nonlinear model that maximizes the likelihood of observing the value of the dependent variable given the values of the independent variables. As such, probit estimates are obtained by the method known as maximum likelihood estimation.
The probit model makes four basic assumptions. First, the error term is normally distributed. With this assumption, the probit estimates have a set of properties similar to those of OLS estimates (e.g., unbiasedness, normal sampling distributions, minimum variance). Second, the probability that the dependent variable takes on the value 1 (given the choices 0 and 1) is a function of the independent variables. Third, the observations of the dependent variable are statistically independent. This rules out serial correlation. Fourth, there are no perfect linear dependencies among the independent variables. As with OLS, near but not exact linear dependencies may result in multicollinearity.
Although probit estimates appear similar to those of OLS regression, their interpretation is less straightforward. Probit estimates are probabilities of observing a 0 or 1 in the dependent variable given the values of the independent variables for a particular observation. The coefficient estimate for each independent variable is the amount the probability of the dependent variable taking on the value 1 increases (or decreases if the estimate is negative), and it is given in standard deviations, a Z-score, based on the cumulative normal probability distribution. Thus, the estimated probability that y = 1 for a given observation is
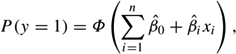
...
- Analysis of Variance
- Association and Correlation
- Association
- Association Model
- Asymmetric Measures
- Biserial Correlation
- Canonical Correlation Analysis
- Correlation
- Correspondence Analysis
- Intraclass Correlation
- Multiple Correlation
- Part Correlation
- Partial Correlation
- Pearson's Correlation Coefficient
- Semipartial Correlation
- Simple Correlation (Regression)
- Spearman Correlation Coefficient
- Strength of Association
- Symmetric Measures
- Basic Qualitative Research
- Basic Statistics
- F Ratio
- N(n)
- t-Test
- X¯
- Y Variable
- z-Test
- Alternative Hypothesis
- Average
- Bar Graph
- Bell-Shaped Curve
- Bimodal
- Case
- Causal Modeling
- Cell
- Covariance
- Cumulative Frequency Polygon
- Data
- Dependent Variable
- Dispersion
- Exploratory Data Analysis
- Frequency Distribution
- Histogram
- Hypothesis
- Independent Variable
- Measures of Central Tendency
- Median
- Null Hypothesis
- Pie Chart
- Regression
- Standard Deviation
- Statistic
- Causal Modeling
- DISCOURSE/CONVERSATION ANALYSIS
- Econometrics
- Epistemology
- Ethnography
- Evaluation
- Event History Analysis
- Experimental Design
- Factor Analysis and Related Techniques
- Feminist Methodology
- Generalized Linear Models
- HISTORICAL/COMPARATIVE
- Interviewing in Qualitative Research
- Latent Variable Model
- LIFE HISTORY/BIOGRAPHY
- LOG-LINEAR MODELS (CATEGORICAL DEPENDENT VARIABLES)
- Longitudinal Analysis
- Mathematics and Formal Models
- Measurement Level
- Measurement Testing and Classification
- Multilevel Analysis
- Multiple Regression
- Qualitative Data Analysis
- Sampling in Qualitative Research
- Sampling in Surveys
- Scaling
- Significance Testing
- Simple Regression
- Survey Design
- Time Series
- ARIMA
- Box-Jenkins Modeling
- Cointegration
- Detrending
- Durbin-Watson Statistic
- Error Correction Models
- Forecasting
- Granger Causality
- Interrupted Time-Series Design
- Intervention Analysis
- Lag Structure
- Moving Average
- Periodicity
- Serial Correlation
- Spectral Analysis
- Time-Series Cross-Section (TSCS) Models
- Time-Series Data (Analysis/Design)
- Trend Analysis
Get a 30 day FREE TRIAL
-
 Watch videos from a variety of sources bringing classroom topics to life
Watch videos from a variety of sources bringing classroom topics to life -
Read modern, diverse business cases
-
Explore hundreds of books and reference titles

Read next

More like this
Sage Recommends
We found other relevant content for you on other Sage platforms.
Have you created a personal profile? Login or create a profile so that you can save clips, playlists and searches