Entry
Reader's guide
Entries A-Z
Multiple Correlation
The multiple correlation arises in the context of MULTIPLE REGRESSION ANALYSIS; it is a one-number summary measure of the accuracy of prediction from the regression model.
In multiple regression analysis, a single dependent variable Y (or criterion) is predicted from a set of independent variables (or predictors). In the most common form of multiple regression, multiple LINEAR REGRESSION (or ORDINARY LEAST SQUARES regression analysis), the independent variables are aggregated into a linear combination according to the following linear regression equation:
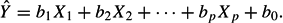
The Xs are the predictors. Each predictor is multiplied by a weight, called the PARTIAL REGRESSION COEFFICIENT, b1, b2,…, bp. Then, according to the regression equation, the linear combination (or weighted sum) of the scores on the set of predictors is computed. This weighted sum, noted ^Y, is termed the predicted score. The regression coefficients b1, b2,…, bp are chosen in such a way that correlation between the actual dependent variable Y and the predicted score ^Y is as large as possible. This maximum correlation between a single criterion score Y and a linear combination of a set of Xs is the multiple correlation, RY^Y. In usual practice, the square of this correlation is reported, referred to as the squared multiple correlation R2Y^Y, or R-SQUARED.
The squared multiple correlation is a central measure in multiple regression analysis—it summarizes the overall adequacy of the set of predictors in accounting for the dependent variable. The squared multiple correlation is the proportion of variation in the criterion that is accounted for by the set of predictors.
As an example, consider an undergraduate statistics course in which three tests are given during the semester. Suppose in a class of 50 students, we predict scores on Test 3 from scores on Tests 1 and 2 using linear regression as the method of analysis. The resulting linear regression equation is as follows:
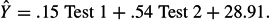
For each student, we substitute the scores on Test 1 and Test 2 into the regression equation and compute the predicted score ^Y on Test 3. We then correlate these predicted scores with actual scores on Test 3; the resulting correlation is the multiple correlation. Here the multiple correlation is RY^Y = .65, quite a substantial correlation. Students' performance on the third test is closely related to performance on the first two tests. The squared multiple correlation R2Y^Y =.42. We would describe this result by saying that 42% of the variation in the observed Test 3 scores is accounted for by scores on Test 1 and Test 2.
The multiple correlation ranges between 0 and 1. As predictors are added to the regression equation, the multiple correlation either remains the same or increases. The multiple correlation does not take into account the number of predictors. Moreover, the sample multiple correlation tends to overestimate the population multiple correlation. An adjusted squared multiple correlation that is less biased (though not unbiased) is given as follows, where n is the number of cases and p is the number of predictors:
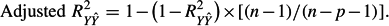
For our analysis with n = 50 students and p = 2 predictors, the adjusted R2Y^Y = .39.
...
- Analysis of Variance
- Association and Correlation
- Association
- Association Model
- Asymmetric Measures
- Biserial Correlation
- Canonical Correlation Analysis
- Correlation
- Correspondence Analysis
- Intraclass Correlation
- Multiple Correlation
- Part Correlation
- Partial Correlation
- Pearson's Correlation Coefficient
- Semipartial Correlation
- Simple Correlation (Regression)
- Spearman Correlation Coefficient
- Strength of Association
- Symmetric Measures
- Basic Qualitative Research
- Basic Statistics
- F Ratio
- N(n)
- t-Test
- X¯
- Y Variable
- z-Test
- Alternative Hypothesis
- Average
- Bar Graph
- Bell-Shaped Curve
- Bimodal
- Case
- Causal Modeling
- Cell
- Covariance
- Cumulative Frequency Polygon
- Data
- Dependent Variable
- Dispersion
- Exploratory Data Analysis
- Frequency Distribution
- Histogram
- Hypothesis
- Independent Variable
- Measures of Central Tendency
- Median
- Null Hypothesis
- Pie Chart
- Regression
- Standard Deviation
- Statistic
- Causal Modeling
- DISCOURSE/CONVERSATION ANALYSIS
- Econometrics
- Epistemology
- Ethnography
- Evaluation
- Event History Analysis
- Experimental Design
- Factor Analysis and Related Techniques
- Feminist Methodology
- Generalized Linear Models
- HISTORICAL/COMPARATIVE
- Interviewing in Qualitative Research
- Latent Variable Model
- LIFE HISTORY/BIOGRAPHY
- LOG-LINEAR MODELS (CATEGORICAL DEPENDENT VARIABLES)
- Longitudinal Analysis
- Mathematics and Formal Models
- Measurement Level
- Measurement Testing and Classification
- Multilevel Analysis
- Multiple Regression
- Qualitative Data Analysis
- Sampling in Qualitative Research
- Sampling in Surveys
- Scaling
- Significance Testing
- Simple Regression
- Survey Design
- Time Series
- ARIMA
- Box-Jenkins Modeling
- Cointegration
- Detrending
- Durbin-Watson Statistic
- Error Correction Models
- Forecasting
- Granger Causality
- Interrupted Time-Series Design
- Intervention Analysis
- Lag Structure
- Moving Average
- Periodicity
- Serial Correlation
- Spectral Analysis
- Time-Series Cross-Section (TSCS) Models
- Time-Series Data (Analysis/Design)
- Trend Analysis
Get a 30 day FREE TRIAL
-
 Watch videos from a variety of sources bringing classroom topics to life
Watch videos from a variety of sources bringing classroom topics to life -
Read modern, diverse business cases
-
Explore hundreds of books and reference titles

Read next

More like this
Sage Recommends
We found other relevant content for you on other Sage platforms.
Have you created a personal profile? Login or create a profile so that you can save clips, playlists and searches