Entry
Reader's guide
Entries A-Z
Mixed-Effects Model
ANALYSIS OF VARIANCE (ANOVA) models can be used to study how a dependent variable Y depends on one or several factors. A factor here is defined as a categorical independent variable—in other words, an explanatory variable with a nominal LEVEL OF MEASUREMENT. Factors can have fixed or random effects. For a factor with fixed effects, the parameters expressing the effect of the categories of each factor are fixed (i.e., nonrandom) numbers. For a factor with random effects, the effects of its categories are modeled as random variables. Fixed effects are appropriate when the statistical inference aims at finding conclusions that hold for precisely the categories of the factor that are present in the data set at hand. Random effects are appropriate when the categories of the factor are regarded as a random sample from some population, and the statistical inference aims at finding conclusions that hold for this population. If the model contains only fixed or only random effects, we speak of FIXED-EFFECTS MODELS or RANDOM-EFFECTS MODELS, respectively. A model containing fixed as well as random effects is called a mixed-effects model.
An example of a mixed-effects ANOVA model could be a study about work satisfaction of employees in several job categories in several organizations. If the researcher is interested in a limited number of specific job categories and in a population of organizations, as well as, inter alia, the amount of variability between the organizations in this population, then it is natural to use a mixed model, with fixed effects for the job categories and random effects for the organizations.
Random effects, as defined above and in the entry on random-effects models, can be regarded as random main effects of the levels of a given factor. Random interaction effects can be defined similarly. In the example from the previous paragraph, a random job category-by-organization interaction effect also could be included.
Mixed-effects models are also used for the analysis of data collected according to SPLIT-PLOT DESIGNS or REPEATED-MEASURES DESIGNS. In such designs, individual subjects (or other units) are investigated under several conditions. Suppose that the conditions form one factor, called B; the individual subjects are also regarded as a factor, called S. The mixed-effects model for this design has a fixed effect for B, a random effect for S, and a random B × S interaction effect.
The Linear Mixed Model
A generalization is a random coefficient of a numerical explanatory variable. This leads to the generalization of the GENERAL LINEAR MODEL, which incorporates fixed as well as random coefficients, commonly called the linear mixed model or random coefficient regression model. In matrix form, this can be written as
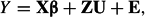
where Y is the dependent variable, X is the design matrix for the fixed effects, β is the vector of fixed regression coefficients, Z is the design matrix for the random coefficients, U is the vector of random coefficients, and E is the vector of random residuals. The standard assumption is that the vectors U and E are independent and have multivariate normal distributions with zero mean vectors and with covariance matrices G and R, respectively. This assumption implies that Y has the multivariate normal distribution with mean Xβ and covariance matrix ZGZ′ + R. Depending on the study design, a further structure will usually be imposed on the matrices G and R. For example, if there are K factors with random effects and the residuals are purely random, then the model can be specialized to
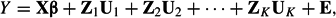
...
- Analysis of Variance
- Association and Correlation
- Association
- Association Model
- Asymmetric Measures
- Biserial Correlation
- Canonical Correlation Analysis
- Correlation
- Correspondence Analysis
- Intraclass Correlation
- Multiple Correlation
- Part Correlation
- Partial Correlation
- Pearson's Correlation Coefficient
- Semipartial Correlation
- Simple Correlation (Regression)
- Spearman Correlation Coefficient
- Strength of Association
- Symmetric Measures
- Basic Qualitative Research
- Basic Statistics
- F Ratio
- N(n)
- t-Test
- X¯
- Y Variable
- z-Test
- Alternative Hypothesis
- Average
- Bar Graph
- Bell-Shaped Curve
- Bimodal
- Case
- Causal Modeling
- Cell
- Covariance
- Cumulative Frequency Polygon
- Data
- Dependent Variable
- Dispersion
- Exploratory Data Analysis
- Frequency Distribution
- Histogram
- Hypothesis
- Independent Variable
- Measures of Central Tendency
- Median
- Null Hypothesis
- Pie Chart
- Regression
- Standard Deviation
- Statistic
- Causal Modeling
- DISCOURSE/CONVERSATION ANALYSIS
- Econometrics
- Epistemology
- Ethnography
- Evaluation
- Event History Analysis
- Experimental Design
- Factor Analysis and Related Techniques
- Feminist Methodology
- Generalized Linear Models
- HISTORICAL/COMPARATIVE
- Interviewing in Qualitative Research
- Latent Variable Model
- LIFE HISTORY/BIOGRAPHY
- LOG-LINEAR MODELS (CATEGORICAL DEPENDENT VARIABLES)
- Longitudinal Analysis
- Mathematics and Formal Models
- Measurement Level
- Measurement Testing and Classification
- Multilevel Analysis
- Multiple Regression
- Qualitative Data Analysis
- Sampling in Qualitative Research
- Sampling in Surveys
- Scaling
- Significance Testing
- Simple Regression
- Survey Design
- Time Series
- ARIMA
- Box-Jenkins Modeling
- Cointegration
- Detrending
- Durbin-Watson Statistic
- Error Correction Models
- Forecasting
- Granger Causality
- Interrupted Time-Series Design
- Intervention Analysis
- Lag Structure
- Moving Average
- Periodicity
- Serial Correlation
- Spectral Analysis
- Time-Series Cross-Section (TSCS) Models
- Time-Series Data (Analysis/Design)
- Trend Analysis
Get a 30 day FREE TRIAL
-
 Watch videos from a variety of sources bringing classroom topics to life
Watch videos from a variety of sources bringing classroom topics to life -
Read modern, diverse business cases
-
Explore hundreds of books and reference titles

Read next

More like this
Sage Recommends
We found other relevant content for you on other Sage platforms.
Have you created a personal profile? Login or create a profile so that you can save clips, playlists and searches