Entry
Reader's guide
Entries A-Z
Fixed Effects Model
ANALYSIS OF VARIANCE (ANOVA) models can be used to study how a dependent variable Y depends on one or several factors. A factor here is defined as a categorical independent variable; in other words, an explanatory variable with a nominal LEVEL OF MEASUREMENT. A fixed effects ANOVA model (also called a Type I ANOVA model) has fixed (i.e., nonrandom) parameters expressing the effect of the categories of each factor. Such a model is appropriate if the statistical inference aims at finding conclusions that hold for precisely the categories of the factors that are present in the data set at hand. This contrasts with RANDOM EFFECTS MODELS, which are described in another article and can be appropriate if the observations of the categories of the factor are a sample from a population. An example of a fixed effects ANOVA model could be a study about work satisfaction of employees depending on gender and a classification in a small number of job categories.
Fixed effects ANOVA models are special cases of the GENERAL LINEAR MODEL, which is basic to REGRESSION analysis. The effects of the categories of a factor in an ANOVA can be expressed as regression coefficients of dummy variables in a regression analysis. The general linear model can be formulated as
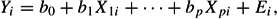
where i indicates the case, Y is the dependent variable, X1 to Xp are the independent (or explanatory) variables, and E is the unexplained part, usually called the residual or error term. The quantity bh is the regression coefficient of variable Xh. The regression coefficients are fixed (i.e., nonrandom) quantities and also are called fixed effects. They are characteristics of the population for which the regression model is defined. Fixed effects occur similarly in other, more complicated models, such as generalized linear models or nonlinear regression models.
There is another reason for modeling effects of a given factor as fixed rather than random, irrespective of whether the categories of the factor can be regarded as a sample from a population. This is for factors or other variables that are not of primary interest for the researcher but that have to be included in the model to achieve a good model specification; such variables are called nuisance variables or control variables. In many cases (depending on the correct model specification), such nuisance variables are better controlled for by including them with fixed effects than with random effects. “Better control” means that the parameters of primary interest can be estimated with less bias, or without bias altogether. One class of examples is panel data, used in econometrics, where, in some studies, the time variable (often the year date) has the role of a nuisance variable, which is controlled for by including it as a fixed effect (see Greene, 2003). Another example is the study about work satisfaction of employees depending on gender and job categories mentioned earlier, now conducted in a (small or large) number of different companies. The companies, if regarded as a nuisance variable, could be treated as a fixed effect. On the other hand, if there is interest in the amount and kind of variability between the companies, they could be included as a random effect, which would lead to a MIXED-EFFECTS model.
...
- Analysis of Variance
- Association and Correlation
- Association
- Association Model
- Asymmetric Measures
- Biserial Correlation
- Canonical Correlation Analysis
- Correlation
- Correspondence Analysis
- Intraclass Correlation
- Multiple Correlation
- Part Correlation
- Partial Correlation
- Pearson's Correlation Coefficient
- Semipartial Correlation
- Simple Correlation (Regression)
- Spearman Correlation Coefficient
- Strength of Association
- Symmetric Measures
- Basic Qualitative Research
- Basic Statistics
- F Ratio
- N(n)
- t-Test
- X¯
- Y Variable
- z-Test
- Alternative Hypothesis
- Average
- Bar Graph
- Bell-Shaped Curve
- Bimodal
- Case
- Causal Modeling
- Cell
- Covariance
- Cumulative Frequency Polygon
- Data
- Dependent Variable
- Dispersion
- Exploratory Data Analysis
- Frequency Distribution
- Histogram
- Hypothesis
- Independent Variable
- Measures of Central Tendency
- Median
- Null Hypothesis
- Pie Chart
- Regression
- Standard Deviation
- Statistic
- Causal Modeling
- DISCOURSE/CONVERSATION ANALYSIS
- Econometrics
- Epistemology
- Ethnography
- Evaluation
- Event History Analysis
- Experimental Design
- Factor Analysis and Related Techniques
- Feminist Methodology
- Generalized Linear Models
- HISTORICAL/COMPARATIVE
- Interviewing in Qualitative Research
- Latent Variable Model
- LIFE HISTORY/BIOGRAPHY
- LOG-LINEAR MODELS (CATEGORICAL DEPENDENT VARIABLES)
- Longitudinal Analysis
- Mathematics and Formal Models
- Measurement Level
- Measurement Testing and Classification
- Multilevel Analysis
- Multiple Regression
- Qualitative Data Analysis
- Sampling in Qualitative Research
- Sampling in Surveys
- Scaling
- Significance Testing
- Simple Regression
- Survey Design
- Time Series
- ARIMA
- Box-Jenkins Modeling
- Cointegration
- Detrending
- Durbin-Watson Statistic
- Error Correction Models
- Forecasting
- Granger Causality
- Interrupted Time-Series Design
- Intervention Analysis
- Lag Structure
- Moving Average
- Periodicity
- Serial Correlation
- Spectral Analysis
- Time-Series Cross-Section (TSCS) Models
- Time-Series Data (Analysis/Design)
- Trend Analysis
Get a 30 day FREE TRIAL
-
 Watch videos from a variety of sources bringing classroom topics to life
Watch videos from a variety of sources bringing classroom topics to life -
Read modern, diverse business cases
-
Explore hundreds of books and reference titles

Read next

More like this
Sage Recommends
We found other relevant content for you on other Sage platforms.
Have you created a personal profile? Login or create a profile so that you can save clips, playlists and searches