Entry
Reader's guide
Entries A-Z
Subject index
Sampling Error
Sampling error consists of two components: sampling variance and sampling bias. Sometimes overall sampling error is referred to as sampling mean squarederror (MSE), which can be decomposed as in the following formula:
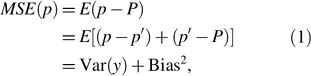
where P is the true population value, p is the measured sample estimate, and p' is the hypothetical mean value of realizations of p averaged across all possible replications of the sampling process producing p.
Sampling variance is the part that can be controlled by sample design factors such as sample size, clustering strategies, stratification, and estimation procedures. It is the error that reflects the extent to which repeated replications of the sampling process result in different estimates. Sampling variance is the random component of sampling error since it results from "luck of the draw" and the specifie population elements that are included in each sample. The presence of sampling bias, on the other hand, indicates that there is a systematic error that is present no matter how many times the sample is drawn.
Using an analogy with archery, when all the arrows are clustered tightly around the bull's-eye we say we have low variance and low bias. At the other extreme, if the arrows are widely scattered over the target and the midpoint of the arrows is off-center, we say we have high variance and high bias. In-between situations occur when the arrows are tightly clustered but far off-target, which is a situation of low variance and high bias. Finally, if the arrows are on-target but widely scattered, we have high variance coupled with low bias.
Efficient samples that result in estimates that are close to each other and to the corresponding population value are said to have low sampling variance, low sampling bias, and low overall sampling error. At the other extreme, samples that yield estimates that fluctuate widely and vary significantly from the corresponding population values are said to have high sampling variance, high sampling bias, and high overall sampling error. By the same token, samples can have average level sampling error by achieving high levels of sampling variance combined with low levels of sampling bias, or vice versa. (In this discussion it is assumed, for the sake of explanation, that the samples are drawn repeatedly and measurements are made for each drawn sample. In practice, of course, this is not feasible, but the repeated measurement scenario serves as a heuristic tool to help explain the concept of sampling variance.)
Sampling Variance
Sampling variance can be measured, and there exist extensive theory and software that allow for its calculation. All random samples are subject to sampling variance that is due to the fact that not all elements in the population are included in the sample and each random sample will consist of a different combination of population elements and thus will produce different estimates. The extent to which these estimates differ across all possible estimates is known as sampling variance. Inefficient designs that employ no or weak stratification will result in samples and estimates that fluctuate widely. On the other hand, if the design incorporates effective stratification strategies and minimal clustering, it is possible to have samples whose estimates are very similar, thereby generating low variance between estimates, thus achieving high levels of sampling precision.
...
- Ethical Issues In Survey Research
- Anonymity
- Beneficence
- Cell Suppression
- Certificate of Confidentiality
- Common Rule
- Confidentiality
- Consent Form
- Debriefing
- Deception
- Disclosure
- Disclosure Limitation
- Ethical Principles
- Falsification
- Informed Consent
- Institutional Review Board (IRB)
- Minimal Risk
- Perturbation Methods
- Privacy
- Protection of Human Subjects
- Respondent Debriefing
- Survey Ethics
- Voluntary Participation
- Measurement - Interviewer
- Measurement - Mode
- Measurement - Questionnaire
- Aided Recall
- Aided Recognition
- Attitude Measurement
- Attitude Strength
- Attitudes
- Aural Communication
- Balanced Question
- Behavioral Question
- Bipolar Scale
- Bogus Question
- Bounding
- Branching
- Check All That Apply
- Closed-Ended Question
- Codebook
- Cognitive Interviewing
- Construct
- Construct Validity
- Context Effect
- Contingency Question
- Demographic Measure
- Dependent Variable
- Diary
- Don't Knows (DKs)
- Double Negative
- Double-Barreled Question
- Drop-Down Menus
- Event History Calendar
- Exhaustive
- Factorial Survey Method (Rossi's Method)
- Feeling Thermometer
- Forced Choice
- Gestalt Psychology
- Graphical Language
- Guttman Scale
- HTML Boxes
- Item Order Randomization
- Item Response Theory
- Knowledge Question
- Language Translations
- Likert Scale
- List-Experiment Technique
- Mail Questionnaire
- Mutually Exclusive
- Open-Ended Question
- Paired Comparison Technique
- Precoded Question
- Priming
- Psychographic Measure
- Question Order Effects
- Question Stem
- Questionnaire
- Questionnaire Design
- Questionnaire Length
- Questionnaire-Related Error
- Radio Buttons
- Random Order
- Random Start
- Randomized Response
- Ranking
- Rating
- Reference Period
- Response Alternatives
- Response Order Effects
- Self-Administered Questionnaire
- Self-Reported Measure
- Semantic Differential Technique
- Sensitive Topics
- Show Card
- Step-Ladder Question
- True Value
- Unaided Recall
- Unbalanced Question
- Unfolding Question
- Vignette Question
- Visual Communication
- Measurement - Respondent
- Acquiescence Response Bias
- Behavior Coding
- Cognitive Aspects of Survey Methodology (CASM)
- Comprehension
- Encoding
- Extreme Response Style
- Key Informant
- Misreporting
- Nonattitude
- Nondifferentiation
- Overreporting
- Panel Conditioning
- Panel Fatigue
- Positivity Bias
- Primacy Effect
- Reactivity
- Recency Effect
- Record Check
- Respondent
- Respondent Burden
- Respondent Fatigue
- Respondent-Related Error
- Response
- Response Bias
- Response Latency
- Retrieval
- Reverse Record Check
- Satisficing
- Social Desirability
- Telescoping
- Underreporting
- Measurement - Miscellaneous
- Nonresponse - Item-Level
- Nonresponse - Outcome Codes And Rates
- Busies
- Completed Interview
- Completion Rate
- Contact Rate
- Contactability
- Contacts
- Cooperation Rate
- e
- Fast Busy
- Final Dispositions
- Hang-Up During Introduction (HUDI)
- Household Refusal
- Ineligible
- Language Barrier
- Noncontact Rate
- Noncontacts
- Noncooperation Rate
- Nonresidential
- Nonresponse Rates
- Number Changed
- Out of Order
- Out of Sample
- Partial Completion
- Refusal
- Refusal Rate
- Respondent Refusal
- Response Rates
- Standard Definitions
- Temporary Dispositions
- Unable to Participate
- Unavailable Respondent
- Unknown Eligibility
- Unlisted Household
- Nonresponse - Unit-Level
- Advance Contact
- Attrition
- Contingent Incentives
- Controlled Access
- Cooperation
- Differential Attrition
- Differential Nonresponse
- Economic Exchange Theory
- Fallback Statements
- Gatekeeper
- Ignorable Nonresponse
- Incentives
- Introduction
- Leverage-Saliency Theory
- Noncontingent Incentives
- Nonignorable Nonresponse
- Nonresponse
- Nonresponse Bias
- Nonresponse Error
- Refusal Avoidance
- Refusal Avoidance Training (RAT)
- Refusal Conversion
- Refusal Report Form (RRF)
- Response Propensity
- Saliency
- Social Exchange Theory
- Social Isolation
- Tailoring
- Total Design Method (TDM)
- Unit Nonresponse
- Operations - General
- Advance Letter
- Bilingual Interviewing
- Case
- Data Management
- Dispositions
- Field Director
- Field Period
- Mode of Data Collection
- Multi-Level Integrated Database Approach (MIDA)
- Paper-and-Pencil Interviewing (PAPI)
- Paradata
- Quality Control
- Recontact
- Reinterview
- Research Management
- Sample Management
- Sample Replicates
- Supervisor
- Survey Costs
- Technology-Based Training
- Validation
- Verification
- Video Computer-Assisted Self-Interviewing (VCASI)
- Operations - In-Person Surveys
- Operations - Interviewer-Administered Surveys
- Operations - Mall Surveys
- Operations - Telephone Surveys
- Access Lines
- Answering Machine Messages
- Call Forwarding
- Call Screening
- Call Sheet
- Callbacks
- Caller ID
- Calling Rules
- Cold Call
- Computer-Assisted Telephone Interviewing (CATI)
- Do-Not-Call (DNC) Registries
- Federal Communications Commission (FCC) Regulations
- Federal Trade Commission (FTC) Regulations
- Hit Rate
- Inbound Calling
- Interactive Voice Response (IVR)
- Listed Number
- Matched Number
- Nontelephone Household
- Number Portability
- Number Verification
- Outbound Calling
- Predictive Dialing
- Prefix
- Privacy Manager
- Research Call Center
- Reverse Directory
- Suffix Banks
- Supervisor-to-interviewer Ratio
- Telephone Consumer Protection Act 1991
- Telephone Penetration
- Telephone Surveys
- Touchtone Data Entry
- Unmatched Number
- Unpublished Number
- Videophone Interviewing
- Voice over Internet Protocol (VoIP) and the Virtual Computer-Assisted Telephone Interview (CATI) Facility
- Political And Election Polling
- 800 Poll
- 900 Poll
- ABC News/Washington Post Poll
- Approval Ratings
- Bandwagon and Underdog Effects
- Call-in Polls
- Computerized-Response Audience Polling (CRAP)
- Convention Bounce
- Deliberative Poll
- Election Night Projections
- Election Polls
- Exit Polls
- Favorability Ratings
- FRUGing
- Horse Race Journalism
- Leaning Voters
- Likely Voter
- Media Polls
- Methods Box
- National Council on Public Polls (NCPP)
- National Election Pool (NEP)
- National Election Studies (NES)
- New York Times/CBS News Poll
- Poll
- Polling Review Board (PRB)
- Pollster
- Pre-Election Polls
- Pre-Primary Polls
- Precision Journalism
- Prior Restraint
- Probable Electorate
- Pseudo-Polls
- Push Polls
- Rolling Averages
- Sample Precinct
- Self-Selected Listener Opinion Poll (SLOP)
- Straw Polls
- Subgroup Analysis
- SUGing
- Tracking Polls
- Trend Analysis
- Trial Heat Question
- Undecided Voters
- Public Opinion
- Agenda Setting
- Consumer Sentiment Index
- Issue Definition (Framing)
- Knowledge Gap
- Mass Beliefs
- Opinion Norms
- Opinion Question
- Opinions
- Perception Question
- Political Knowledge
- Public Opinion
- Public Opinion Research
- Quality of Life Indicators
- Question Wording as Discourse Indicators
- Social Capital
- Spiral of Silence
- Third-Person Effect
- Topic Saliency
- Trust in Government
- Sampling, Coverage, And Weighting
- Adaptive Sampling
- Add-a-Digit Sampling
- Address-Based Sampling
- Area Frame
- Area Probability Sample
- Capture-Recapture Sampling
- Cell Phone Only Household
- Cell Phone Sampling
- Census
- Cluster Sample
- Clustering
- Complex Sample Surveys
- Convenience Sampling
- Coverage
- Coverage Error
- Cross-Sectional Survey Design
- Cutoff Sampling
- Designated Respondent
- Directory Sampling
- Disproportionate Allocation to Strata
- Dual-Frame Sampling
- Duplication
- Elements
- Eligibility
- Email Survey
- EPSEM Sample
- Equal Probability of Selection
- Error of Nonobservation
- Errors of Commission
- Errors of Omission
- Establishment Survey
- External Validity
- Field Survey
- Finite Population
- Frame
- Geographic Screening
- Hagan and Collier Selection Method
- Half-Open Interval
- Informant
- Internet Pop-Up Polls
- Internet Surveys
- Interpenetrated Design
- Inverse Sampling
- Kish Selection Method
- Last-Birthday Selection
- List Sampling
- List-Assisted Sampling
- Log-in Polls
- Longitudinal Studies
- Mail Survey
- Mall Intercept Survey
- Mitofsky-Waksberg Sampling
- Mixed-Mode
- Multi-Mode Surveys
- Multi-Stage Sample
- Multiple-Frame Sampling
- Multiplicity Sampling
- n
- N
- Network Sampling
- Neyman Allocation
- Noncoverage
- Nonprobability Sampling
- Nonsampling Error
- Optimal Allocation
- Overcoverage
- Panel
- Panel Survey
- Population
- Population of Inference
- Population of Interest
- Post-Stratification
- Primary Sampling Unit (PSU)
- Probability of Selection
- Probability Proportional to Size (PPS) Sampling
- Probability Sample
- Propensity Scores
- Propensity-Weighted Web Survey
- Proportional Allocation to Strata
- Proxy Respondent
- Purposive Sample
- Quota Sampling
- Random
- Random Sampling
- Random-Digit Dialing (RDD)
- Ranked-Set Sampling (RSS)
- Rare Populations
- Registration-Based Sampling (RBS)
- Repeated Cross-Sectional Design
- Replacement
- Representative Sample
- Research Design
- Respondent-Driven Sampling (RDS)
- Reverse Directory Sampling
- Rotating Panel Design
- Sample
- Sample Design
- Sample Size
- Sampling
- Sampling Fraction
- Sampling Frame
- Sampling Interval
- Sampling Pool
- Sampling Without Replacement
- Screening
- Segments
- Self-Selected Sample
- Self-Selection Bias
- Sequential Sampling
- Simple Random Sample
- Small Area Estimation
- Snowball Sampling
- Strata
- Stratified Sampling
- Superpopulation
- Survey
- Systematic Sampling
- Target Population
- Telephone Households
- Telephone Surveys
- Troldahl-Carter-Bryant Respondent Selection Method
- Undercoverage
- Unit
- Unit Coverage
- Unit of Observation
- Universe
- Wave
- Web Survey
- Weighting
- Within-Unit Coverage
- Within-Unit Coverage Error
- Within-Unit Selection
- Zero-Number Banks
- Survey Industry
- American Association for Public Opinion Research (AAPOR)
- American Community Survey (ACS)
- American Statistical Association Section on Survey Research Methods (ASA-SRMS)
- Behavioral Risk Factor Surveillance System (BRFSS)
- Bureau of Labor Statistics (BLS)
- Cochran, W. G.
- Council for Marketing and Opinion Research (CMOR)
- Council of American Survey Research Organizations (CASRO)
- Crossley, Archibald
- Current Population Survey (CPS)
- Gallup Poll
- Gallup, George
- General Social Survey (GSS)
- Hansen, Morris
- Institute for Social Research (ISR)
- International Field Directors and Technologies Conference (IFD&TC)
- International Journal of Public Opinion Research (IJPOR)
- International Social Survey Programme (ISSP)
- Joint Program in Survey Methodology (JPSM)
- Journal of Official Statistics (JOS)
- Kish, Leslie
- National Health and Nutrition Examination Survey (NHANES)
- National Health Interview Survey (NHIS)
- National Household Education Surveys (NHES) Program
- National Opinion Research Center (NORC)
- Pew Research Center
- Public Opinion Quarterly (POQ)
- Roper Center for Public Opinion Research
- Roper, Elmo
- Sheatsley, Paul
- Statistics Canada
- Survey Methodology
- Survey Sponsor
- Telemarketing
- U.S. Bureau of the Census
- World Association for Public Opinion Research (WAPOR)
- Survey Statistics
- Algorithm
- Alpha, Significance Level of Test
- Alternative Hypothesis
- Analysis of Variance (ANOVA)
- Attenuation
- Auxiliary Variable
- Balanced Repeated Replication (BRR)
- Bias
- Bootstrapping
- Chi-Square
- Composite Estimation
- Confidence Interval
- Confidence Level
- Constant
- Contingency Table
- Control Group
- Correlation
- Covariance
- Cronbach's Alpha
- Cross-Sectional Data
- Data Swapping
- Design Effects (deff)
- Design-Based Estimation
- Ecological Fallacy
- Effective Sample Size
- Experimental Design
- F-Test
- Factorial Design
- Finite Population Correction (fpc) Factor
- Frequency Distribution
- Hot-Deck Imputation
- Imputation
- Independent Variable
- Inference
- Interaction Effect
- Internal Validity
- Interval Estimate
- Intracluster Homogeneity
- Jackknife Variance Estimation
- Level of Analysis
- Main Effect
- Margin of Error (MOE)
- Marginals
- Mean
- Mean Square Error
- Median
- Metadata
- Mode
- Model-Based Estimation
- Multiple Imputation
- Noncausal Covariation
- Null Hypothesis
- Outliers
- p-Value
- Panel Data Analysis
- Parameter
- Percentage Frequency Distribution
- Percentile
- Point Estimate
- Population Parameter
- Post-Survey Adjustments
- Precision
- Probability
- Raking
- Random Assignment
- Random Error
- Raw Data
- Recoded Variable
- Regression Analysis
- Relative Frequency
- Replicate Methods for Variance Estimation
- Research Hypothesis
- Research Question
- Rho
- Sampling Bias
- Sampling Error
- Sampling Variance
- SAS
- Seam Effect
- Significance Level
- Solomon Four-Group Design
- Standard Error
- Standard Error of the Mean
- STATA
- Statistic
- Statistical Package for the Social Sciences (SPSS)
- Statistical Power
- SUDAAN
- Systematic Error
- t-Test
- Taylor Series Linearization
- Test-Retest Reliability
- Total Survey Error (TSE)
- Type I Error
- Type II Error
- Unbiased Statistic
- Validity
- Variable
- Variance
- Variance Estimation
- WesVar
- z-Score
- Loading...
Get a 30 day FREE TRIAL
-
 Watch videos from a variety of sources bringing classroom topics to life
Watch videos from a variety of sources bringing classroom topics to life -
Read modern, diverse business cases
-
Explore hundreds of books and reference titles

Read next

More like this
Sage Recommends
We found other relevant content for you on other Sage platforms.
Have you created a personal profile? Login or create a profile so that you can save clips, playlists and searches